
Mambas & Transformers: what it means for application builders.
Introduction
In 2017, Google published a deep learning architecture called Transformer. It revolutionised the fields of Artificial Intelligence and Machine Learning. Fast forward to 2024: transformer-based Large Language Models (LLMs) power routinely used chatbots able to understand and answer using natural language. The Transformer architecture is so successful that some believe it won’t be dethroned for the next few years.
Although successful, transformer-based models suffer from efficiency issues. As the length of the input sequence increases, the generation of text becomes slower: your chatbot becomes slower as the conversation becomes longer. Clever techniques (e.g., flash attention, caching, sliding window) and specialised hardware allow to go further, but, ultimately, transformers are subjected to an efficiency bottleneck.
Then, last December, came Mamba. It is a new architecture, reminiscent of the pre-transformer era Recurrent neural networks, able to process very long sequences. Note that Mamba is not a “transformer with long sequences” — it is a different kind of model, with different weaknesses and strengths. Our view is that many future LLM applications will use both, side by side, for different purposes.
High Level View
Large Language Models (LLMs) are text completion systems which, given an input sequence, produce an output sequence. The input and output sequences are made of tokens. A token is not a letter nor a word, but a sequence of characters. When interacting with an LLM, the input text is first converted into tokens before being passed on to the LLM. Similarly, the tokens generated by the LLM are converted back to text.
Both transformer-based models and mamba-based models generate tokens iteratively, one by one. The generation process stops when a condition is met, such as the generation of a specific token, or reaching a given output length. They, however, differ in how they process their input.
Transformers
A transformer-based model reads the input sequence, processes it, generates an output token, adds the token to the sequence, and starts the process all over again.
When an output token is generated, the transformer has access to all the preceding tokens, made of the initial input sequence and all the tokens it generated. Every time a token is appended to the sequence, it “interacts” with all previous tokens.
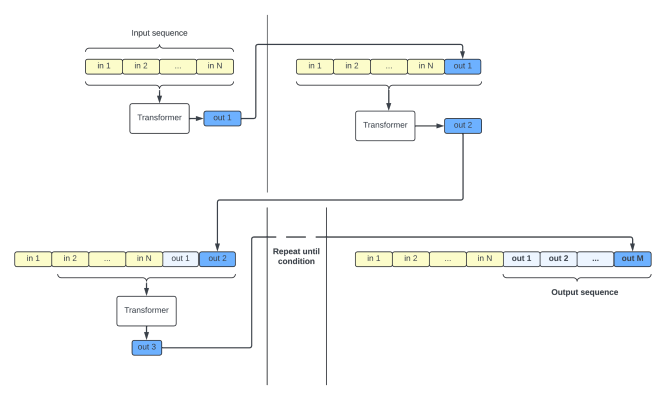
This growing sequence is commonly called the “context”. A transformer-based chatbot (e.g., ChatGPT) context usually contains a system prompt (instructing it how to behave), then your conversation made of your messages AND the chatbot’s answers. It all goes in!
This principle is both the strength and the weakness of the transformers: because it has access to all the input at all times, a transformer can have (in theory) perfect recall of everything mentioned. However, it must also process the full (and growing!) sequence for every generated token, which is the source of its inefficiency.
Mamba
Mamba models read the input sequence token by token, iteratively updating a “state,” a form of internal memory. At any point in time, only the previous state and a token are required to produce an output token. The model never “sees” the full sequence at once. Instead, it compresses and encodes it in the state
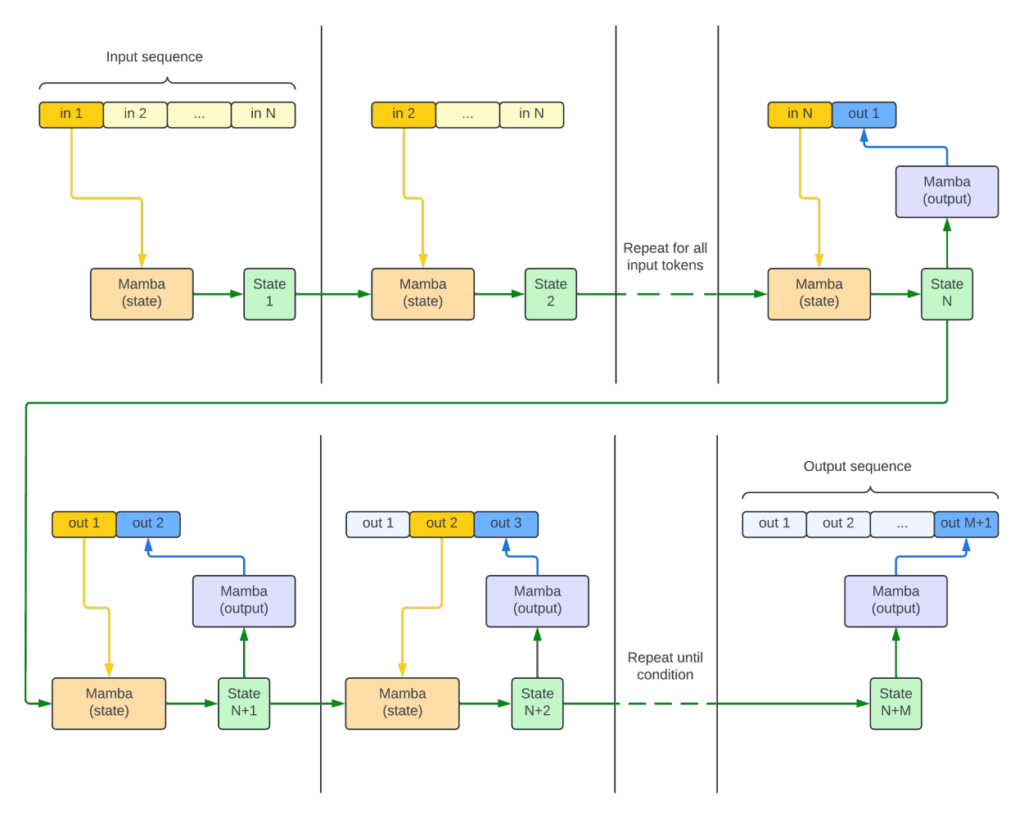
The complexity of a mamba does not grow with the context, and hence it can process longer sequences than a transformer. On the other hand, it has to make an immediate decision about recording the token’s information in its state, and it can’t have perfect recall of the input as it is loosely compressed.
Implication for application builder
Considering the technical differences between Mamba and Transformer models, what implications emerge for application developers?
Intuition of difference
Imagine taking an exam on a book, where you must answer two types of questions: one about the book’s overall content (e.g., “What is the name of the main character?”) and another about specific details in the text (e.g., “What is the first punctuation mark following the 37th occurrence of the word ‘house’?”). The first type depends on general understanding, while the second requires precise recall.
Transformer models are taking an open-book exam: they have access to the full book and can reference and quote the exact text. They decide what to focus on when generating an output token, and this focus can shift during generation; something initially deemed unimportant may become crucial later. This flexibility is possible because all information is always accessible. Thus, transformers can address both types of questions effectively.
Mamba models, on the other hand, are taking an open-notes exam: they read the book, making notes on key points, and later depend on these notes. If an information is not immediately recorded, it is lost. They can answer the first kind of question but might struggle with questions requiring detailed recall.
If a transformer is more precise, why use a mamba? You don’t have to: if all necessary information fits within a transformer’s context and other factors (like speed and cost) are suitable for your needs, then there’s no need for a mamba. In other situations, mamba architectures can offer advantages in speed, cost, and handling long contexts. However, instead of choosing one over the other, it may be more beneficial to use both, considering their unique strengths:
- Transformers are ideal as conversational assistants: they remember the exact recent history of a conversation. Their perfect recall ability is crucial for tasks requiring precise writing, such as code assistants or writers’ helpers. However, they struggle with long contexts. They can be the short-term memory part of an artificial brain.
- Mambas excel with long sequence: they manage their own memory, selectively recording and compressing information. They can be the long-term memory of an artificial brain.
It’s worth noting that solutions like memGPT are being developed to address transformers’ long-term memory challenges. We believe Mamba will integrate well into such systems!
Let’s imagine how could we use mambas!
Notice one very interesting property of Mamba: you have access to the state (the green squares in the second image), i.e., to all of the information the model recorded while reading some input. This means it’s possible to precompute the state for a potentially huge input, and then continuously reuse it.
States instead of embedding?
Notice one very interesting property of Mamba: you have access to the state (the green squares in the second image), i.e., to all of the information the model recorded while reading some input. This means it’s possible to precompute the state for a potentially huge input, and then continuously reuse it.
States instead of fine-tuning?
Fine-tuning adapts a model to a specific domain by updating the network’s weights. Currently, LoRa adapters are used, for example, to personalise the style of an image generation network. Alternatively, we could envision creating a Mamba state by feeding several images into the network, then using this state (possibly with a different network) to create an image in the style recorded in the state. In this regard, Mamba architectures can be seen as being programmable by states!
Multiple States?
We can also look at what is currently happening with transformers and imagine that similar practices could be applied to the states of Mamba (and Mamba itself).
Take the concept of the concept of Mixture of Experts. We can envision a Mixture of States: Mambas with multiple states, each acting as an expert or knowledge base. Extending the “programmable by state”s idea, some states could be read-only and act solely as instructions. Imagine one state capturing the description of a book, and another state embodying a graphic style. We could ask a model to create an illustration of any book in any style simply by swapping the states.
Merging States?
Layers from different transformers are successfully being merged. We could try to apply the same concept to states. For example, two graphic styles could be merged into a new one by combining their corresponding states.
Conclusion
We believe that Mambas aren’t meant to replace Transformers, but rather to complement them. While both architectures have areas of overlap and can be used in various scenarios, they also possess distinct strengths. Exploiting both architectures allows to create applications that wouldn’t be feasible with just one of them. It is more productive to view them as partners rather than competitors!

Matthieu
Matthieu leads the research and work related to Generative AI for onepoint in Asia-Pacific.